 手机访问:wap.265xx.com
手机访问:wap.265xx.com多对多多语言神经机器翻译的对比学习
原创作者 | 朱林
论文解读:
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
论文作者:
Xiao Pan, Mingxuan Wang, Liwei Wu, Lei Li
论文地址:
https://aclanthology.org/2021.acl-long.21.pdf
收录会议:
ACL2021
目前机器翻译的研究热点仍然集中在英语与其他语言翻译的方向上,而非英语方向的研究成果仍然寥寥无几。
如何有效利用不同语言的特征去构建模型,提高多种语言,尤其是非英语之间的翻译水平是个越发重要的课题。
传统思路中,为了解决两种语言机器翻译问题,人们往往分别学习这两种语言的特征再匹配,而忽略了两种语言在特征表达上的较大差异,导致模型效果较差。
本篇ACL会议论文提出了一种统一多语言翻译模型mRASP2来改进翻译性能,利用多语言对比学习能综合表达的优点改进了机器翻译性能,尤其提高了非英语方向的翻译质量。
该模型由两种技术支撑:
(1)对比学习,用于缩小不同语言表示之间的差距;
(2)对多个平行语料和单语语料进行数据增强,以进一步对齐标记表示。
实验表明,以英语为中心的方向,mRASP2模型的性能优于现有的最佳统一模型,并且在WMT数据集的数十个翻译方向上的性能超过了当前性能顶尖的mBART模型。
在非英语方向,与Transformer基线模型相比,mRASP2也实现了平均10 BLEU(性能指标)以上的性能改进。
mRASP2需要输入一对平行句子(或增强伪平行句子),并使用多语言编解码器计算交叉熵损失。此外,它计算正样本和随机生成的负样本的对比损失,总体框架如图1所示:
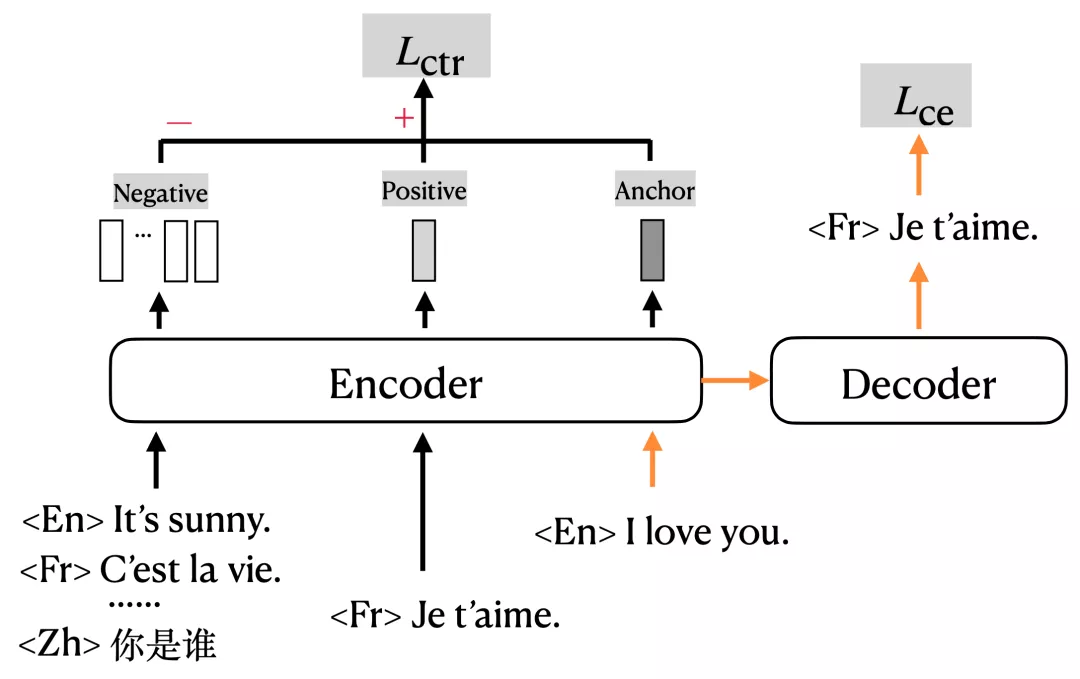 图1 mRASP2模型
图1 mRASP2模型
 图2 通过替换同义词词典中具有相同含义的单词,对平行数据和单语数据进行对齐增强。生成包括伪平行示例(左)和伪自平行示例(右)。
图2 通过替换同义词词典中具有相同含义的单词,对平行数据和单语数据进行对齐增强。生成包括伪平行示例(左)和伪自平行示例(右)。
多语言转换器
模型采用了多语言神经机器翻译(Neural Machine Translation, NMT)模型学习多对多映射函数f,以将一种语言翻译成另一种语言。
为了区分不同的语言,作者在每个句子之前添加了一个额外的语言识别标记,用于源端和目标端。
mRASP2的基础架构采用的是最先进的Transformer模型。与之前的相关工作略有不同,作者选择了12层编码器和12层解码器,更多的层数可以增加模型的容量。
为了简化深度模型的训练,作者对编码器和解码器的Word Embedding和Pre-norm Residual Connection应用Layer Normalization。
因此,作者的多语言NMT比Transformer模型强得多。
作者定义了
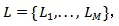 其中L是涉及训练阶段的M种语言的集合。
其中L是涉及训练阶段的M种语言的集合。
 表示
表示
 的平行数据集,
的平行数据集,
D表示所有平行数据集。该模型训练的损失函数采用了交叉熵的形式,定义为:
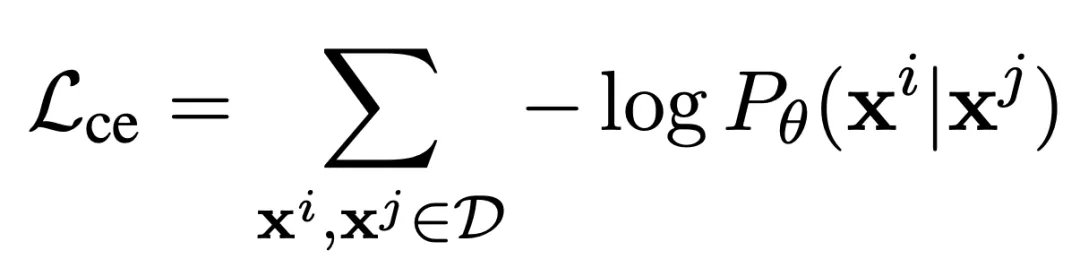 其中
其中
 语言中的一个句子,
语言中的一个句子,
 是多语言Transformer模型的参数。
是多语言Transformer模型的参数。
多语言对比学习
模型采用了多语言转换器来隐式地学习不同语言的共享表示。mRASP2引入了对比损失来明确地将不同的语言映射到共享的语义空间。
对比学习的关键思想是最小化相似句子的表示差距,最大化不相关句子的表示差距。
形式上,给定一个双语翻译对是正样本,
 对比学习的目标是最小化以下损失:
对比学习的目标是最小化以下损失:
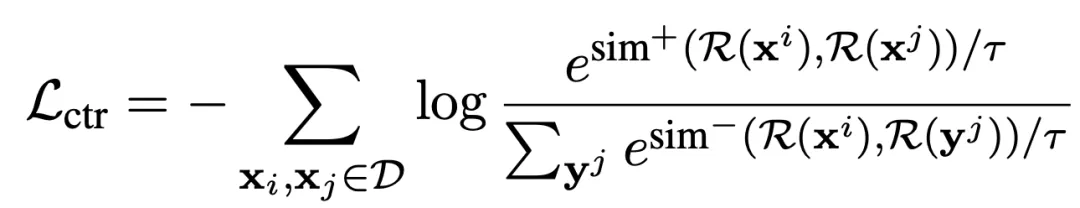
其中sim(.)计算不同句子的相似度。+和-分别表示正样本还是负样本。
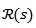 表示任意句子s的平均池化编码输出。
表示任意句子s的平均池化编码输出。
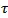 控制着区分正样本和负样本的难度。
控制着区分正样本和负样本的难度。
在mRASP2的训练过程中,可以通过联合最小化对比训练损失和翻译损失来优化模型:
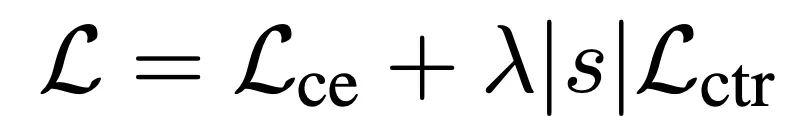 其中λ是平衡两个训练损失的系数。
其中λ是平衡两个训练损失的系数。
 对齐增强
对齐增强
作者基于前人提出的随机对齐替换(Random Aligned Substitution, RAS)技术——一种为多语言预训练构建代码切换句

 以英语为中心的方向
以英语为中心的方向
表1和表2中罗列了作者实验中得到的具有代表性的多个翻译方向的性能增益结果。
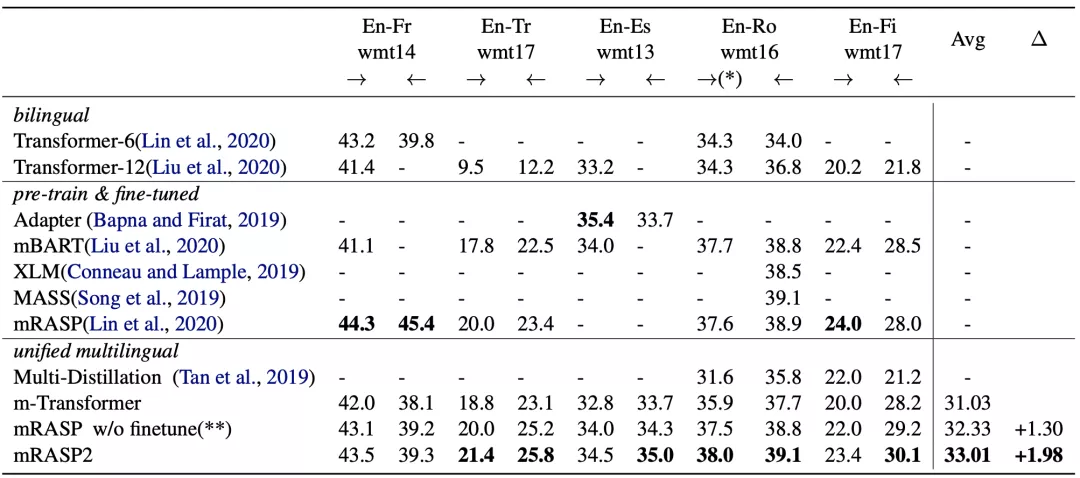 表1 监督翻译方向上的性能对比。
表1 监督翻译方向上的性能对比。
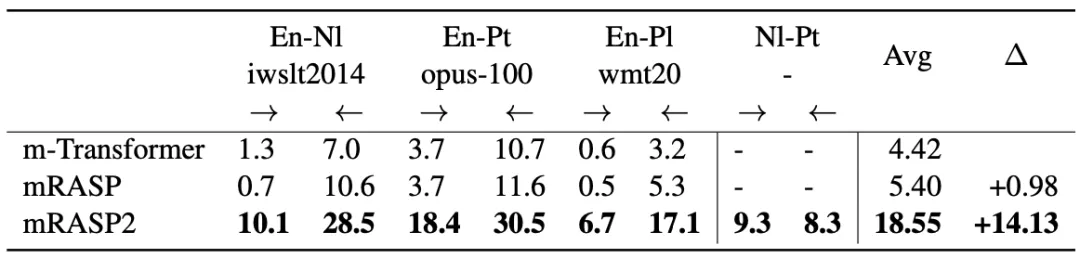 图2 attention score 和attribution score 示意图
图2 attention score 和attribution score 示意图
监督翻译如表1所示,mRASP2在10个翻译方向上显著提高了多语言机器翻译的基线。以前,多语言机器翻译在资料丰富的场景中表现不佳。
作者总结了其成功训练的关键因素包括:
(1)提高了训练批次:每批包含大约300万个词;
(2)增大了模型层数:从6层扩大到了12层;
(3)使用正则化方法来稳定训练。
无监督方向如表2所示,作者观察到mRASP2在无监督翻译方向上取得了明显有效的结果。实验中,m-Transformer模型永远不会观察到En-Nl、En-Pt和En-Pl的语言对,即它在En→X的翻译方向上完全无效。相比之下,mRASP2平均获得+14.13BLEU分数,而没有明确引入这些方向的监督信息。
此外,mRASP2在NlPt方向上获得了明显有效的BLEU分数,即使它只在双方的单语数据上进行了训练。这表明通过在统一框架中简单地将单语数据与平行数据合并,mRASP2就可以成功地实现了无监督翻译。
上一篇:近日,永堌镇、官桥镇、杨楼镇做了这些工作
下一篇:11月5日报名截止!复旦大学2023年度基础教育系统教师招聘及优秀人才引进启动
最近更新学历教育
- 首个无短板超短焦投影诞生?坚果O2超短焦系列以颠覆之名叫板激光电视
- 抢抓机遇、担当作为、勇争一流,推动高质量发展保持良好势头 武汉市扎实开展第二批主
- 早教机构、物业服务问题突出
- 第三届“一带一路”国际合作高峰论坛贸易畅通专题论坛取得丰硕经贸成果
- 人流榜单!沈阳人流医院哪家好排名“公开发布”沈阳人流好的医院公开
- 哈市开展“环卫工人安全作业”交通安全宣传活动
- 托福阅读试题陷阱解析
- 必须规范使用!中传文化管理学院发表十点倡议,引导广大学子规范使用AIGC
- 内心的渴望是与故土永远厮守
- 洛阳职业技术学院:医教协同培养基层健康“守门人”
- 山东青州:有温度,有力度,这样的教育真给力!
- 吉林省吉林市:发放购房补贴,打击抹黑唱衰楼市的不当言论
- 托福独立作文的结构
- 多国音乐家昆明共享“有一种叫云南的生活”
- 凝心聚力 有“备”而来
- 春城少年丨现场开题现场写文,五年级学生如何应对?
- 长沙市开福区清水塘江湾小学:用阅读浸润孩子们的童年
- 英国热门留学专业牛校推荐
- “红色沂蒙·时尚临沂”打造今日“琅琊榜”
- 贾丁:把山西医科大学爱尔眼视光学院打造成校企合作、培养人才的典范
- 青岛啤酒原料仓疑被工人小便污染,律师:可能涉嫌破坏生产经营罪,或处七年以下有期徒
- 今日辟谣
- “上海论坛2023”年会回归线下 倡导跨国界、跨学科、跨领域对话
- 重庆118名运动员出征第五届全国智力运动会 合川区将承办第六届全国智力运动会
- 一家3口全部感染!成人也会中招,有人肺部出现大片炎症……