 手机访问:wap.265xx.com
手机访问:wap.265xx.com4k 75fps!实时超分算法助力S12赛事直播
前言:2022年英雄联盟S12全球总决赛于9月29日拉开帷幕,赛事直播间吸引了大批量英雄联盟忠实粉丝。为了给玩家们提供更好的观赛体验,我们研发了一种面向S12赛事直播的实时画面超分算法来提升画面质量。该算法能够在源流的基础上使得画面细节更加清晰、纹理更加丰富,可以将视频从1080p超分至4k分辨率的同时达到75fps的实时处理速度。
01 轻量化游戏直播
实时画面超分模型设计
图像超分算法在业内不是新方向,它主要分为非实时和实时处理两种类型。经常能够看到一些超分算法将年代久远、画质较差、噪声较多的老旧视频处理成分辨率更高、清晰度较好、符合主流审美的新视频。这类超分算法的使用场景往往追求更清晰的视频观看体验,它们基于充足的算力,能够让老旧视频焕发新生。但是非实时超分算法的计算量普遍比较大,只能适用于对于实时性没有要求的场景。而在游戏直播场景中,就必须用到能够实时处理的超分网络了。
在面对1080p@60fps的游戏直播源流时,需要考虑的不仅仅是超分效果,还需要达到高实时性,这的确是一个不小的挑战。应用于离线点播ESR(Efficient Super-Resolution)模型网络的研究已经相对成熟,但它们基本不满足直播场景的实时性要求,我们在应用于点播业务的超分模型的基础上进行了重构,其主要结构如下图所示。
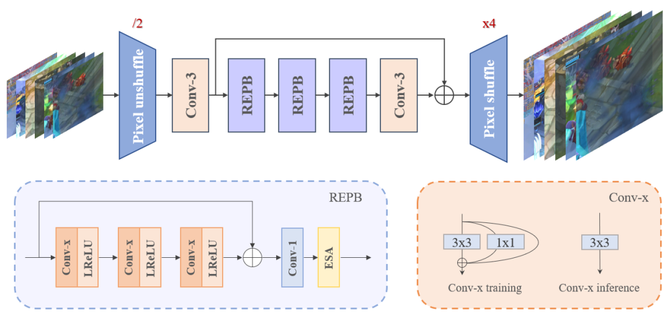
图1. 面向游戏直播视频的实时超分网络结构示意图
为了达到实时处理的目的,模型的参数量被尽可能地压缩,但是较少的参数量也意味着较弱的模型拟合能力。目前主流的超分网络在模型处理阶段的特征图是不会采取下采样操作的,然而实验证明在这种特征图不缩小的设定下能满足实时要求的超分模型结构在效果上往往差强人意。
为了达成更优的性能与推理耗时之间的均衡,我们所提出的模型首先通过pixel unshuffle操作缩小特征图尺寸,这样可以在保证模型参数量一定的情况下进一步减少计算量,加速推理过程。在网络处理的最后阶段通过pixel shuffle操作对图像进行重建以实现超分效果。pixel unshuffle与pixel shuffle的结构示意图如图2所示,可以看出在特征图转换的过程中这种对偶操作计算量极小,且该过程是信息无损、且可逆的(可求导)。
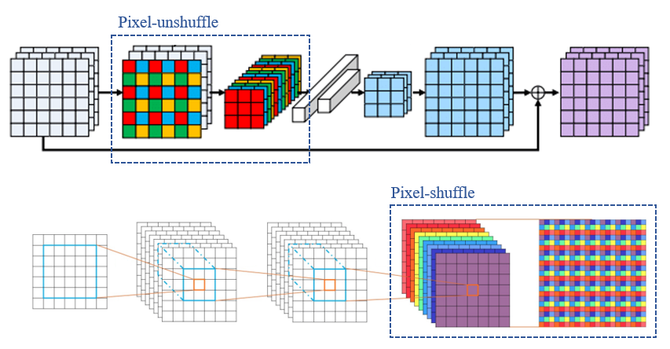
图2. Pixel-unshuffle/Pixel-shuffle结构示意图
同时我们在模型压缩中也借鉴了结构重参数化的思想,让训练网络的多路结构转化为推理网络的单路结构,进一步加快推理速率。这种处理机制既保留了多分支网络在训练时的性能优势,也发挥了单路网络在推理时速度快、省内存的好处。
在训练过程中基础模块包含conv3*3结构、conv1*1残差结构以及identity残差结构,残差结构的多个分支相当于给网络增加了多条梯度流动,一方面使得网络更加易于收敛,另一方面增强了模型的拟合能力。在推理过程中通过Op融合策略(如图3所示)可以将这三个分支转换为单个conv3*3结构以便于部署和网络加速。
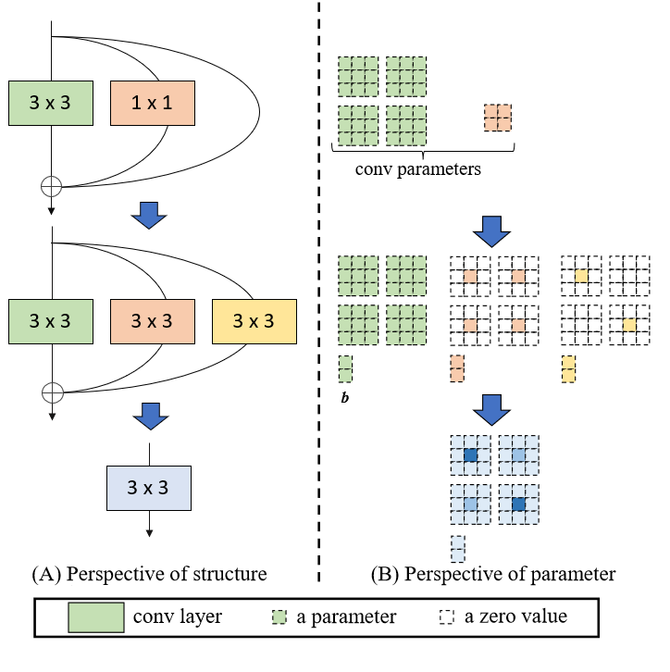
图3. Op融合策略示意图
02 面向纹理细节保护
的损失函数的设计
训练过程中我们采用了Multi-Loss的策略对以上网络进行训练,除了常规的L1 损失函数(L1 loss)外,还引入了感知损失函数(Perceptual loss)、基于Sobel的纹理损失函数(Sobel-based texture loss)、以及对抗损失函数(GAN loss)。
仅采用L1损失函数训练出的超分网络往往会导致输出图片过于平滑,容易丢掉高频细节部分。图4为训练过程中保存的快照,从左至右依次为低质图像、超分图像、高质图像、以及高质图像与超分图像的残差图。
可以发现网络在图像高频部分通常存在较大偏差,这在超分图像上就会表现为纹理不够清晰,细节丢失等现象。我们将这种现象称为Blurred Average,并对其产生原因做如下解释:对于深度学习网络来说像素与像素之间没有较大的主次差别,如果在训练过程中没有对网络进行额外引导,网络会对所有像素“一视同仁”,又因为低频信号在画面中占了较大比重,所以网络在训练时会偏重于低频信号的重建,而在高频信号上表现较差。

图4. 低质图像/超分图像/高质图像/残差图像
为了更好地保护游戏画面的纹理细节,我们在训练过程中针对性地加入了如下两个损失函数,以平衡网络对高低频信号的关注。
Perceptual loss:其核心思想是基于一个已经训练好的具备感知和语义信息能力的网络来计算生成图像与真值图像特征之间的距离。理想情况下重建的高分辨率图像与真实的高分辨率图像无论在低层次像素值上,还是高层次抽象特征上都应当接近。所以在对纹理进行重建的过程中同时使用高层全局信息以及底层细节信息,即所说的感知特征来对网络进行训练往往会取得更好的效果。
Sobel-based texture loss:其目的是为了主动引导网络去加强对于高频纹理信号的关注,更有效地去学习纹理特征,所以利用sobel边缘检测算子检测真值图像灰度图的边缘,并依据计算出的梯度值对L1 loss进行加权来计算损失,这样便使得训练的时候其中绝大部分的loss贡献来源于图像中的边缘。
图5是针对损失函数进行消融实验的对比图像,左图在训练过程中仅基于L1 loss进行反向梯度计算,右图则加入了Perceptual loss和Sobel-based texture loss,可以明显看出网络在纹理细节表现上的提升。

图5. 纹理细节对比图
在整个训练过程中我们还使用了基于GAN的对抗训练方法,通过GAN loss对模型参数进行finetune训练,在生成器和判别器的对抗迭代优化中,使得超分网络(生成器)输出的数据分布更加接近真实数据的分布。
03 多阶段热启动模型训练策略
在超分模型训练过程中我们制作了两个数据集:数据集Ⅰ和数据集Ⅱ,每个数据集由大量高质量-低质量图像对组成。
其中数据集Ⅰ的高质数据是录制的高清游戏场景画面,低质数据是通过对高质视频设置不同的crf参数,添加gaussian噪声、jpeg噪声、上下采样等操作制作出来的。
数据集Ⅱ的低质数据是直接拉取的线上直播的低清视频流,而它的高质数据则是经过一个训练较好的非实时超分网络超分后的结果。
训练过程主要包括三个阶段:模型预热、模型精调、毛刺调整。整个网络训练的配置如表1所示。在模型预热阶段,我们基于数据集Ⅰ对网络进行预训练,此时Perceptual loss和Sobel-based texture loss暂不开启,其主要目的是利用L1 loss将网络快速拟合到一个超分/去噪能力尚可的基线水平。而在训练约50个epoch后,再开启Perceptual loss和Sobel-based texture loss,并使用一个较小的学习率在数据集Ⅱ上对模型进行精调。值得注意的是此时训练数据集的低质数据是与实际应用场景下的直播视频流具有高度相似性的,这将有助于网络更好地学习有针对性的重建技巧。最后毛刺调整阶段,为了针对画面中存在的毛刺噪声进行精细去噪,我们通过GAN的训练方法,进一步降低学习率并在数据集Ⅰ上对模型进行微调,从而减弱毛刺,增强画面质感。

表1 面向游戏直播的超分网络训练配置表
04 总结与展望
游戏直播是B站的重点业务,英雄联盟S12赛事直播更是吸引了大量人气。为了给广大用户带来更好的音视频服务体验,我们针对S12赛事直播的场景特点定制化开发了一种极高效率的在线超分算法,能够实时地将低清的游戏画面转化为画质更优的高清画面,呈现出更丰富的纹理以及更清晰的细节,给用户提供更好的观看体验。
单卡4k 75fps的实时超分速度拓宽了超分技术在直播领域的应用。当前该算法仅在S12官方赛事直播间应用,而在未来我们还能将它快速低成本地迁移到更多的需要较高实时性的游戏直播业务中,此外还可以结合三次元超分算法来扩展开更为广阔的应用空间,敬请期待。
最近更新继续教育
- 黄山屯溪区:秋风迎诗意 教研唤灵思
- 给您提个醒!社保待遇资格认证别忘了办,认证时间可以自己挑个好记的日子
- 雄安新区城市鸿蒙生态正式启动!
- 打破规模天花板:复杂科学怎样框定企业幂律增长路线图?
- 根植文化自信 福建师大少数民族学生与艺术名家面对面
- 兰大师生参加第18届锕系及裂片核素在地圈中的化学与迁移行为国际会议
- 祝贺!兰大校友吴照华夺得2023年世界武搏运动会男子刀棍全能金牌
- 以更强信心冲刺决战目标
- 原创突发!记者曝出争议猛料,球迷吐槽:中超联赛就是个天大的笑话
- 观烟台·观商务丨刚刚,烟台在这里温情亮相
- 华中科技大学校长尤政:校友已成为学校的一张亮丽名片,和一笔宝贵财富
- 66年血脉情缘历久弥深,“交大”回来了丨西南交通大学唐山园区正式启用
- 朱钰峰出席第十三届苏港澳青年发展论坛
- 新西兰留学申请
- 自主与合资企业频出招,海外出口成弱势车企“救心丸”
- 托福写作如何得高分
- 海南大学海洋科学与工程学院院长沈义俊:培养海洋科技人才 助力海南海洋强省建设
- 综测推免双第一,保研上财,她用行动创造不凡
- @毕业生:收藏好这份秋招指南 让你“遥遥领先”
- 托福雅思哪个难考
- moto razr 斩获双 11 小折叠多项销量第一,还公布全新智变柔性屏新机
- 着眼国家战略需求培养高素质人才
- 促进贸易畅通 推动经贸合作迈上新台阶
- 双峰县教育系统:厚德仁爱尊老爱贤 凝心聚智共谋振兴
- 郝明金出席上海中华职业教育社第七次代表会议