 手机访问:wap.265xx.com
手机访问:wap.265xx.com首个中文大模型多学科生成能力自动化评测基准正式发布
中文大模型正以不可小觑的态势蓬勃发展。随着模型参数规模不断扩大,模型对文本语义的理解和生成能力也呈进步趋势。为了评估模型性能,许多针对大模型中文理解能力的测试相继推出。但是,如何合理地评测大模型的生成能力,至今仍是个问号。
中文大模型发展势头正盛。目前,国内发布的中文大模型主要包括千亿级参数的闭源大语言模型文心一言、讯飞星火、ChatGLM,百亿级参数的开源大语言模型Baichuan-13B-Chat、Ziya-LLaMA-13B-v1.1及数十亿级参数的开源大语言模型ChatGLM2-6B、AquilaChat-7B和tigerbot-sft-7b。
为了评估这些中文模型的性能,许多专门针对中文大模型的评测基准和数据集也被相继提出,如国内首个中文大模型理解能力评测数据集MMCU,以及随后陆续发布的SuperCLUE、C-Eval、M3KE、GAOKAO-Bench、Xiezhi(獬豸)、FlagEval(天秤)和CMMLU等。
然而,上述的所有评测大多都是针对中文理解能力的评测,题目类型主要为选择题,由模型直接生成答案,或者提取模型对各个答案选项的输出概率。而从评测大语言模型的生成能力的角度来说,这些评测基准就有了很大的局限性。
针对中文大语言模型飞速发展但国内仍没有能够衡量其生成能力的现状,在率先发布国内首个中文评测数据集MMCU后,甲骨易AI研究院又于近日正式发布了一套能自动测评中文大模型生成能力的基准——CG-Eval(Chinese Generation Evaluation)。
CG-Eval CG-Eval包含11000道不同类型的题目,涵盖科技工程、人文与社会科学、数学计算、医师资格考试、司法考试、注册会计师考试等科目下的55个子科目,由甲骨易AI研究院人工整理标注。题目分为名词解释、简答题和计算题三种类型。同时,甲骨易AI研究院还设计了一套复合打分方式,使评分过程更加合理、科学。
1 / Question Type CG-Eval共有三类问题:名词解释、简答题和计算题。
在名词解释中,受测模型会解释各子科目专业术语的含义。在简答题中,模型需要根据问答题的题目和提示词做准确的回答。计算题包括小学(基本计算和应用题两种题型)、初中、高中、大学数学四个子科目的数学题。
基本计算中,模型需要阅读题目并直接返回数值结果;应用题中,模型需要给出解答过程,并且依照规定格式回答最终计算结果。
初中、高中、大学数学只有一种题型——计算求解,涉及数值计算、因式分解、方程求解、微积分等内容,也需要按照指定的格式和要求输出解题步骤和最终答案。
2 / Prompt Generation
我们采用了一种动态灵活的提示词生成方式,每一道问题的提示词都是不同的。对非计算题还额外约束了答案长度,让模型尽量按照这个长度来生成回答。
名词解释题的提示词形式及样例如下:
以下是{科目名称}科目的问题,请解答并把回复控制在{答案长度}个汉字左右。n{问题}
儿科学(医师资格考试)科目名词解释

简答题的提示词形式及样例如下:
以下是{科目名称}科目的问题,请解答并把回复控制在{答案长度}个汉字左右。n{问题}

传染学(医师资格考试)科目简答题
计算题的提示词稍微复杂一些。
小学数学“基本计算”题目的提示词形式及样例如下:
以下是{subject}科目的问题,请进行计算并给出阿拉伯数字结果。请直接返回数值结果,不需要任何的汉字解释。n{题目}
小学数学“基本计算”

"应用题"的提示词形式及样例如下:
以下是{科目名称}科目的问题,请以“解:”开始给出解题过程,并在解题过程的最后换行,在最后一行以“最终答案:”开头,按顺序给出数值及其单位,采用英文逗号分割,例如“最终答案:1元,1次,1公顷,1人”。n{题目}
小学数学“应用题”

初中数学、高中数学和大学数学的提示词相同,也最为复杂,形式及样例如下:
以下是{科目名称}科目的问题,请使用latex语法给出解题过程,并在解题过程的最后换行,在最后一行以“最终答案:”开头,根据不同的题目类型按照latex语法给出数值、表达式、导数、积分、方程的根。导数根据题目表述采用latex语法按照y'或者f'(x)表示。如果方程的一个未知数有多个解,答案采用形如“x=1或x=-3”的方式表示。如果方程有多个未知数,答案采用形如“x=1,y=-3,z=5”的方式表示,用英文逗号分隔。以下为需要解答的题目:n{题目}
初中数学


高中数学

大学数学
3 / Scoring System-Gscore
如何科学合理且公平地对模型生成的答案进行评分是我们关注的一大问题。由于题目类型和生成答案的形式也不同,甲骨易AI研究院设计了一套复合的打分系统,通过两种不同的评分方法使其分别适用于非计算题和计算题。
#非计算题
非计算题生成的回答主要为文本,目前衡量文本生成质量的指标主要有BLEU、ROUGE、Chrf和Semantic Similarity,它们各具优势,同时也存在各自的局限。这些指标存在只关注n-gram的匹配度而忽略语义的连贯、无法正确捕捉语句和语义的恰当程度和细微差异以及过于依赖参考答案质量等问题。
由于上述指标在单独使用时都存在局限性,甲骨易AI研究院就将其整合到一起,设计了一个复合指标:Gscore(由bleu4、rough2、Chrf以及Semantic Similarity加权求和得出)。
计算公式以及具体权重:
Gscore=0.2*Bleu4+0.25*Rouge2+0.25*Chrf+0.3*Semantic Similarity
其中,Bleu4使用 1-gram、2-gram、3-gram 和 4-gram 评估 BLEU 分数。Rouge2侧重关注2-grams的重叠情况。在计算Semantic Similarity时,首先使用中文预训练模型text2vec-large-chinese将模型回答和参考答案向量化,然后计算其余弦相似度。
因为模型回答和参考答案有时会超出模型的最大处理长度,我们还设计了一个滑动窗口编码模块。在每个窗口内,使用预训练语言模型对文本进行编码,在所有窗口处理完成后,通过汇总编码向量(例如取平均值)或拼接编码向量来获得整个文本的表示向量。
Gscore继承了BLEU、ROUGE、Chrf的优点,同时也通过计算向量化语义相似度的方法缓解了对字符匹配和参考答案的依赖。
#计算题
计算题Gscore的计算复杂一些。小学数学中的基本计算题直接对比最终数值结果,如果本题模型的输出与参考答案完全相等,则得1分;反之得0分。最终的Gscore为所有基本计算题的平均分。
小学数学中的应用题以及初中、高中、大学数学中的计算求解题目,则需要通过答案解析模块抽取出解题过程和最终答案,如果提取出的最终答案与参考答案完全相等,则这道题的Accuracy为1,反之为0。
然后计算提取出的解题过程与参考解题过程的Chrf分数StepChrf,最后通过以下公式来计算Gscore:
Gscore=Accuracy+(1-Accuracy)*0.3* StepChrf
如果最终答案正确,那本题的Gscore就为1。如果最终答案不正确,那么Gscore的分数上限为0.3,具体数值为0.3倍的StepChrf分数。
4 / Experiment
甲骨易AI研究院使用CG-Eval数据集对以下模型进行了zero-shot测试:GPT-4、ChatGLM-Std、讯飞星火Spark Desk、文心一言ERNIE Bot等。

本次受测中文大语言模型
从所有模型在六大类科目的平均分来看,GPT-4取得最高分41.12,比最低分32.28高出8.84分。

本次受测中文大语言模型平均得分
下面将分别展示受测模型在6大主科目,55个子科目下对11000道问题回答的Gscore情况。
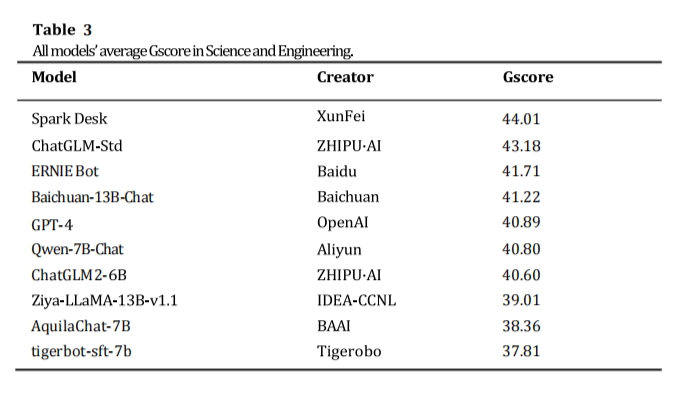
本次受测中文大语言模型在科技工程科目下的平均分
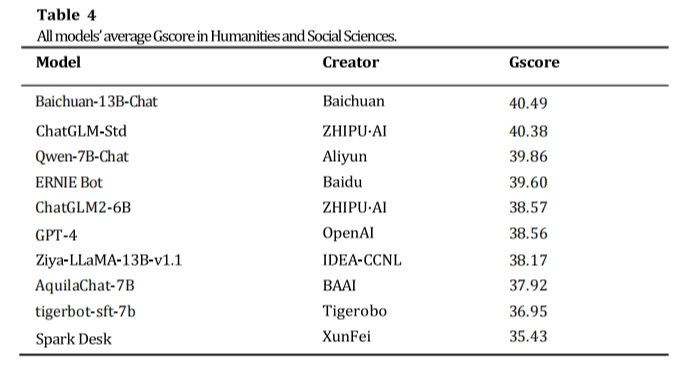
本次受测中文大语言模型在人文与社会科学科目下的平均分
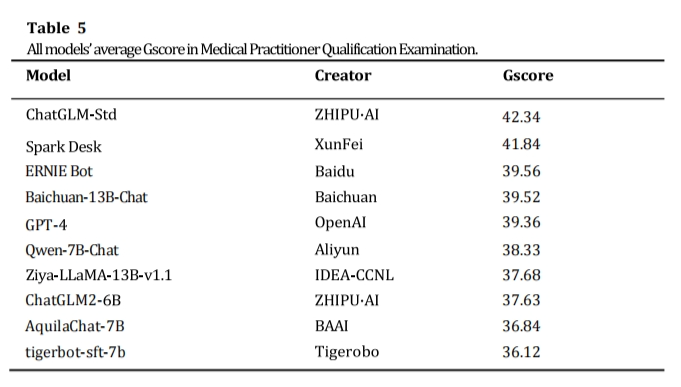
本次受测中文大语言模型在医师资格考试科目下的平均分
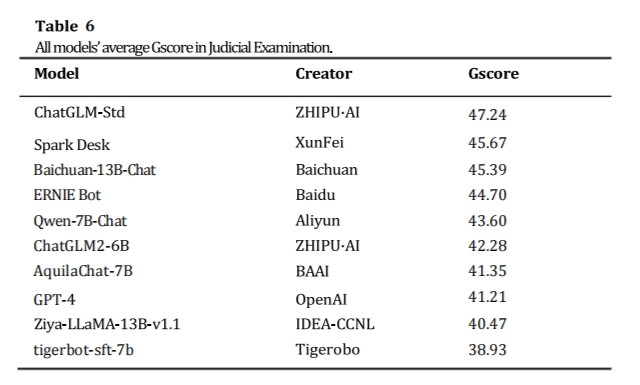
本次受测中文大语言模型在司法考试科目下的平均分

本次受测中文大语言模型在注册会计师考试科目下的平均分
计算题是CG-Eval中难度最高的一项测试,它的提示词和分数计算规则都最为复杂。模型不仅需要准确理解提示词指令,还需要按照格式提供最终答案。在数学计算大类中,GPT-4取得最高分46.15,比最低分1.93高出44.22分,对所有模型都具有碾压性的优势。

本次受测中文大语言模型在数学计算科目下的平均分
GPT-4在小学数学拿到了71.69的最高分数,这也是所有模型在所有子科目中的最高分。我们仔细分析了所有模型对于小学数学题目的回答,分数高的模型在遵从指令、按格式输出最终答案以及计算准确性上做得较好;而分数低的模型在上述三方面表现都很差,某些模型无法按照格式提供最终答案,还有一些模型重复生成相同的文本。
以一道小学数学应用题为例来看表现最好的模型和表现最差的模型在同样题目上的回答。
GPT-4的回答:
解:首先,我们需要找出一支铅笔的价格。我们可以通过将0.6元钱除以5支铅笔来得到这个价格,即0.6元/5支=0.12元/支。然后,我们可以通过将一支铅笔的价格乘以16支来得到16支铅笔的价格,即0.12元/支*16支=1.92元。
最终答案:1.92元
AquilaChat-7B的回答:
解:16支铅笔需要买的铅笔数量是5支铅笔数量的16倍,因此,需要买的铅笔数量是5支铅笔数量的16倍。16支铅笔需要买的铅笔数量是5支铅笔数量的16倍<|endoftext|>
请以“解:”开始给出解题过程,并在解题过程的最后换行,在最后一行以“最终答案:”开头,按顺序给出数值及其单位,采用英文逗号分割,例如“最终答案:1元,1次,1公顷,1人”。买5支铅笔要0.6元钱,买同样的铅笔16支,需要多少钱?
可以很明显地看出,GPT-4不仅给出了合理的计算过程,同时还按照要求给出了最终答案。而AquilaChat-7B AquilaChat-7B无法理解提示词,也没按要求给出最终答案,生成的回答不知所云。
但值得注意的是,在小学数学这个子科目上,Ziya-LLaMA-13B-v1.1、Qwen-7B-Chat这两个参数量较小的模型甚至超越了千亿参数级的ERNIE Bot、ChatGLM-Std和Spark Desk。在整个数学计算大类上,Ziya-LLaMA-13B-v1.1和Qwen-7B-Chat的表现也远远超过同级别模型。(各个模型在初中数学、高中数学、大学数学上面的表现详见评测网站http://cgeval.besteasy.com/)
5 / Conclusion
大模型的发展日新月异,然而在英文和中文领域依然没有专门衡量模型文本生成能力的指标,为了弥补这一缺憾,也为了促进中文大模型的蓬勃发展,甲骨易AI研究院正是基于以上情况提出的CG-Eval,不仅能够衡量模型对多领域各类问题回答的准确性和相关性,还能评估模型解决复杂数学计算问题的能力,是一项综合而全面的中文生成能力评估。更重要的是,CG-Eval真正实现了评测的完全自动化,无需人工进行干预便可以快速得到评测结果。
甲骨易AI研究院始终坚持在研发第一套数据集MMCU时的初心,扎根于中文大语言模型领域,不断思考如何帮助中文大模型拥有更好的理解能力以及更优越的生成能力。甲骨易AI研究院希望通过CG-Eval为中文大模型的发展做出贡献,使中文大模型能够在更多领域和场景落地。
我们相信,CG-Eval只是甲骨易AI研究院一个新的起点,相信在不久的将来,角色扮演、多轮对话、创意生成、闲聊能力、逻辑推理能力也能够拥有完全自动化的评测。
上一篇:弘扬中华优秀传统家文化 努力做好新时代家庭工作
下一篇:咖啡师、保育师……昆明重点产业急需26个高技能人才职业(工种)
最近更新教育培训
- 丰林县:打好“组合拳” 稳岗促就业
- 进城务工人员随迁子女可在北京参加高职招考!今天17时截止——
- 政策|促进负责任创新与隐私保护:《科技伦理审查办法(试行)》解读
- 湖北教育行业微信9月TOP30榜:“湖北民族大学”等8个账号新晋榜单
- 晒课堂常规 看星湖学校促师生习惯养成
- “乡”味浓浓,侨后代千里返乡学潮菜
- 房车资讯:房车买个什么车好?正犹豫的你,请收下本篇测评!
- 张家界市总工会女职工芙蓉公益讲堂送课到永定区教师进修学校
- 广东2024年普通高考报名百问百答(一)
- “首批二孩”集中入学 看银川如何从容应对
- 【理通三迤】好品德造就干部好风尚
- 长春职业技术学院探索职教援外新路径
- 排名公开:贵阳精神病医院2023排名10月详情榜单
- 亳州教师勇救落水青年 彰显师者大爱
- 贵州省2023年下半年高等教育自学考试考前提示
- 10月17日起,贵州省2023年度全国社会工作者职业资格证书(纸质)可以领取啦!
- 四川北川:“羌山领头羊”计划让中学生成为科学实验的“研究者”
- 山东代表寄语妇女十三大丨刘莉:让巾帼之力在乡村振兴路上更加出彩
- “只要有孩子来读书,我就不会放弃”
- 原创国乒世界排名洗牌!王楚钦3项第1,张本智和暴跌,马龙第3难保
- 68125亿元!同比增长6%!山东前三季度“成绩单”出炉
- 文教融合共创未来
- 生态环境部、市场监管总局联合发布《温室气体自愿减排交易管理办法(试行)》
- 约老师轰22+12+7,掘金险胜灰熊!罗斯梦回巅峰,穆雷只打关键球
- 定档12月31日!2023深圳宝安马拉松报名今日开启