 手机访问:wap.265xx.com
手机访问:wap.265xx.com12小时上线“新冠肺炎同程查询工具”,开发者这样狙击疫情

“扩散!急寻这235个车次、航班同行人”
“紧急寻人!急寻Z264、Z265列车同行人!”
“急寻同行旅客,这趟到琼海的动车发现确诊患者”
……
新型肺炎潜伏期长则14天,春运高峰大大增加了疫情防控难度。一条条跳动在新闻上的患者同行信息,就是一个个防控疫情的关键节点。
狙击疫情,必须分秒必争!
信息不断更新,来源多样繁杂,如何让人们快速确认是否与新型肺炎确诊患者同行,从而迅速进行诊断和隔离?1月27日,一款由几位开发者从上午11点紧急开发,到晚上11点已在朋友圈传播的“新型肺炎同程查询工具”就已上线——输入日期、车次以及地区,即可查询是否与已披露的确诊患者同行。
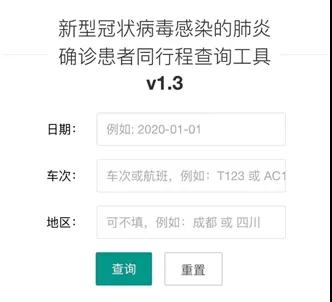
网站:http://2019ncov.nosugartech.com/
“有人是医务人员,所以他们去了;有人是警察,所以他们去了。我们是工程师,我们可以用自己的技能做一些力所能及的小事,希望可以帮到大家”。今天,阿里妹采访到成都无糖信息技术有限公司联合创始人兼CTO,也是工具的开发者童永鳌。在他的故事里,我们看到了中国开发者的力量。

童永鳌在办公
工具上线后,累计访问量已突破3500万次,并获得人民日报的点赞转发。
做力所能及的小事,帮助大家共度难关
阿里妹:能否简单介绍新冠病毒确诊患者同程查询工具的开发初衷?
童永鳌:最开始的原因很单纯,就我自己有查询需求。我们日常接触到的疫情信息里包含寻找患者的同程者这块内容一般就是以图片为载体,一张图罗列了患者曾经搭乘过的交通工具、车次、日期等信息。通过图片逐条查找信息,一来是有可能看漏信息,二来是查找起来确实不太方便,每次都要从头查找。

作为一个程序员,我比较“懒”,一条条的去翻历史记录很麻烦,于是就想到把数据抠下来,用搜索工具去查找更加方便。
阿里妹:工具开发团队是如何在短时间内建立起来的,团队里都是志愿者吗?
童永鳌:最初的团队成员都是我自己认识十多年的老网友。我们原本就在一个群里,平时会闲聊。我看到央视的新闻之后,就在群里说了想要做个工具的想法。他们也非常支持,就直接开始做。团队中还有一个人是我公司的,因为工具需要运行维护,我就把公司的运维主管拉进来。也考虑过志愿者,但如果一开始公开招募的话,整个周期会很长。
最开始我画了一张简单的布局图丢到群里,把前端、后端、数据收集的工作安排出去就立马开始干活了。其实是一种很简单、粗暴的方式。后面陆续加入一些志愿者,他们看到工具之后,通过邮件的方式联系,并加入我们。我们再把这些志愿者拉到群里,他们协助我们收集整理数据。
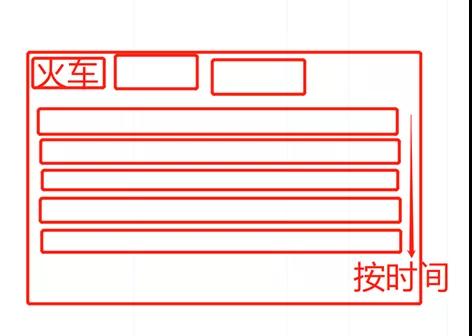
最初大家在群里讨论工具时手画的简单原型图
阿里妹:能否分享一下查询工具最开始的设计思路?
童永鳌:工具本身用到的技术比较简单。先把网上现有的图片和文字内容统一做信息整合,放到数据库中。然后再做一个检索工具,就成了现在大家看到的样子。
一开始并没有想太多,总体思路很直接。有想法之后就立刻开始动手搭建网页。先是在网上查找公开的信息,交通工具就包含:火车、飞机、公交车、出租车等。所以,初步设计数据库中可能用到的这些字段。
接下来就是考虑用户可能会用什么方式来查询,查询的关键词等。我就把自己当成用户,假设自己使用这个工具的话,我需要查些什么?我想到的第一点是日期,先查询我哪天乘坐交通工具。第二点就是贴合车次做具体检索。另外是地区搜索,如果用户在某个位置,那么这个地区的火车、飞机等是否存在已确诊患者。
前面两点是后台数据库设计,最后就是界面设计。考虑完这两个设计,就直接开始动手做了。
阿里妹:从开始到工具上线过程大概用了多少时间?上线后有哪些工作要做?
童永鳌:开发大概用了半天,1月27日 上午11点左右有了这个想法,下午5点左右,功能上基本就已经做好了。后来又花了6个小时整理数据,晚上11点就发朋友圈了。
后期维护上花费的时间比较多,团队成员每天都会花17个小时甚至更久来维护,这几天大家基本上早上9点到晚上2点都在工作。刚开始确实没想到数据会突然增多,信息量大了之后我们就要做一些功能上的加强,比如:处理数据流畅机制、改动代码以及回复网友邮件等。事情多又相对比较杂,但是每一件事情都必须仔细对待。
阿里妹:开发和维护的过程中遇到过哪些挑战?
童永鳌:最大的挑战来自于数据整理。这个工具在初版的时候,用到的数据是央视整理过的,数据是现成的,整理起来相对容易些。后期信息量越来越大,整理信息的难度也越来越大。现在我们也会靠自己去筛选信息。一方面通过爬虫做信息初筛,另一方面靠网友给我们反馈信息。我们会要求网友提供链接,把链接批量爬虫回来后,从链接中做一些信息提取的工作。从目前的数据来看,爬虫来的信息和网友提供的信息大概是五五分。
另外一个挑战来自于访问量的暴涨,完全没想到访问量会这么大。第二天访问量开始暴增的时候,最开始的版本架构就扛不住了。
阿里妹:能简单说下访问量的增长过程吗?面对流量暴涨,是怎么扛过去的?
童永鳌:1月28号是上线第二天,访问总量是450万。第二天晚上八点开始就是一个几何级数的增长,从一个小时10万访问量跳到300万。29号和30号总量在2000万左右。
最开始用的是的朋友的服务器,一兆带宽1G内存。上线第一天,因为配置太低,无法容纳100人同时在线的访问量。后来就直接调用第三方的CDN,我们嵌入远程资源,就不用自己扛资源访问的这一块流量。但随着访问量越来越高,我们发现单台服务器要扛千万级的流量很难做。 于是我们取了个巧,把页面和数据文件生成静态的。相当于把库里的数据生成一个静态的文件,再把页面和数据都放到阿里云的OSS上面。让阿里云的OSS对象存储去扛住高并发、高流量,我们自己就不用担心流量压力了。
阿里妹:需要录入的信息大概多少?如何确保数据的准确性?
童永鳌:总量在500-600条左右。最早的信息是100多条,现在已录入300多条。后端还没录入的信息大概还有250-300条左右,待录入的信息中包括重复的。
数据确认是一个漏斗状的筛选过程。网上搜集来的信息经过验证、去重后会越来越少。数据量大的时候用自动化方式采集,数据量小就可以直接通过人工采集。在审核步骤上大概过程是:初始线索 -> 网友整理 -> 内部人员整理(核实纠正普遍性错误)-> 内部人员录入(核实单条错误)-> 提交(审核单条错误)-> 复查(有原文链接失效或新闻报道后续修改的情况)。
后来人民日报推送工具的时候,他们帮我们重新把数据认真地再审核一遍。
对于信息我们会逐层把关,越到后面关键的步骤,数据把关人越少越好。人越多的话,犯错的可能性也随着增大。而且中间涉及到一个信任问题,特别是后面的审核的这个步骤,除了我最信任的朋友和公司的制作人,没让其他人介入。
在时间上,现在录入速度没有之前那么快了。因为我们对数据的准确性要求越来越严格,需要花大量的时间去核实。对我们来说,及时性排第二位,准确性才是第一位。
阿里妹:对工具的性能会做什么改进吗?
童永鳌:现阶段最主要的还是后端数据,首先是准确性,其次是及时性。功能上并没有打算把它复杂化。如果有些新想法,可能会单独去做尝试。
当然,还是希望疫情能够早点结束,就不用考虑这些啦。
阿里妹:接下来会迎来一个返程高峰,有没有大流量的预备方案?
童永鳌:我们现在已经不太担心高并发、大流量的问题了,主要是对数据的准确性要求更高。我们自己现在录入做数据的时候,感觉已经有点强迫症了,精神高度紧张,生怕敲了一个数字,需要反复确认。
阿里妹:这次疫情来势凶猛,你认为开发者的参与对于阻止疫情的蔓延起到了哪些帮助?
童永鳌:这个比较难判断。假设我是工具的使用者,我也只是做个查询确认而已。至于它对疫情起到多大的帮助,我感觉不出来。我觉得医生是最有帮助的,而工具能够给大家提供一定的参考意义,我觉得就足够了。 这两天也收到一些网友的邮件,有的很简单,就四个字:谢谢你们。看着其实很暖心。
阿里妹:作为一个老开发者,有没有什么建议可以分享给同行?
童永鳌:这几天也没有时间、精力想太多。我想,对于程序员来说,写代码不能当成一份工作,应该当它是一个工具。从这个角度,很容易想到做疫情同乘者查询工具,因为我只是拿一个编程语言来解决我自己想解决的生活中的问题而已,并不是说我要做一个什么项目,从产品角度去考虑这件事。
对开发者来说,建议他们尝试把编程变成了解决日常生活需求的一个东西,而不是单纯地看成工作去对待,可能就会有更多的东西好出来。
共抗疫情,我们能赢
“能做事的做事,能发声的发声。有一分热,发一分光。”疫情没有旁观者。感谢开发者们用科技的力量点亮星光。
在新型肺炎同程查询工具之外,阿里妹还看到了,GitHub上的「wuhan2020」防疫信息收集平台,以及目前还在征集开发者的外来人员登记系统、消毒检查登记系统、学生健康报备管理系统、违纪举报系统、物资管理系统等项目。
我们诚挚邀请所有开发者集思广益,如果你有能帮助到战胜疫情的小工具、好想法,欢迎在下方留言。共抗疫情,我们能赢!
上一篇:洛阳启动吸入式新冠疫苗接种!(接种单位名单)
下一篇:如何区分新冠和普通感冒?多喝水多睡觉对新冠管用吗?答案揭晓
最近更新热点资讯
- 谷歌AI聊天记录让网友San值狂掉:研究员走火入魔认为它已具备人格,被罚带薪休假
- 豆瓣9.4,姐弟恋、三人行,这部大尺度太厉害
- Genes, Intelligence, Racial Hygiene, Gen
- 【土耳其电影】《冬眠》电影评价: 宛如一部回归伯格曼风格的道德剧
- 陌生人社会伦理问题研究
- 理论研究|前海实践的价值理性和工具理性
- 澳门刑事证据禁止规则
- 综艺普及剧本杀和密室逃脱助力线下实体店爆发式增长
- 日本小伙和五个小姐姐同居?看完我酸了!
- 第一学期高一语文考试期中试卷
- 高中必考的物理公式有哪些
- 这部大尺度的申奥片,却讲述了不lun恋...
- 心理语言学论文精品(七篇)
- 《贵妃还乡》 超清
- 专论 | 郭丹彤、陈嘉琪:古代埃及书信中的玛阿特观念
- 微专业招生 | 数字文化传播微专业列车即将发车,沿途课程抢先看!
- 生态安全的重要性汇总十篇
- 原创因“18禁”电影登舆论顶峰,万千少女一场春梦:这一生,足够了
- 章鱼头
- 读书心得体会
- 考研考北京大学医学部或者协和是一种怎样的难度?
- 央媒评女主播编造“夜宿故宫”:让肇事者付出代价,理所应当
- 库欣病患者求医记(流水账)
- 《太平公主》④ | 地位越高,越要装傻
- 爱体检 安卓版 v2.5