 手机访问:wap.265xx.com
手机访问:wap.265xx.com归一化后和标准化后数据到底发生了什么变化?
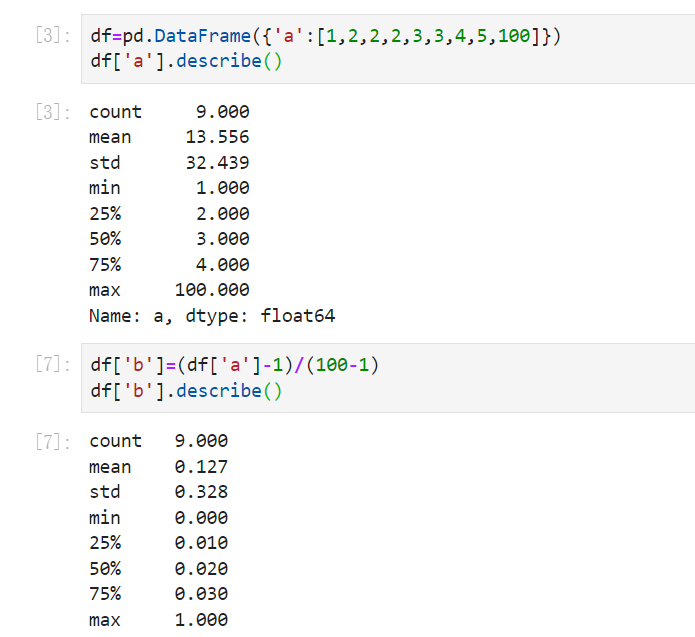
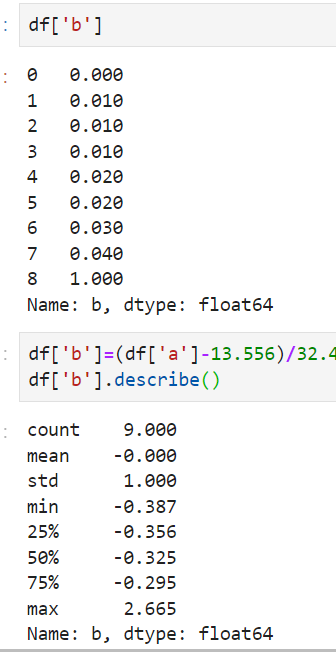
原数据:

一、归一化
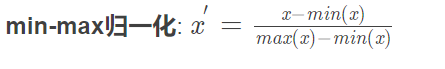
1)画图的时候限制xlim(-2,10) 2)画图的时候去掉xlim的限制
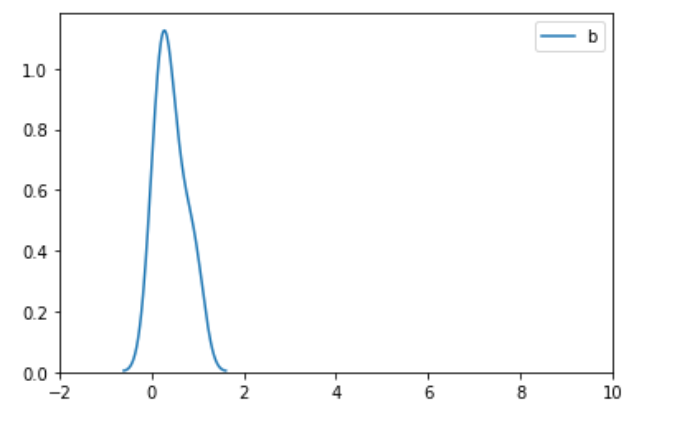
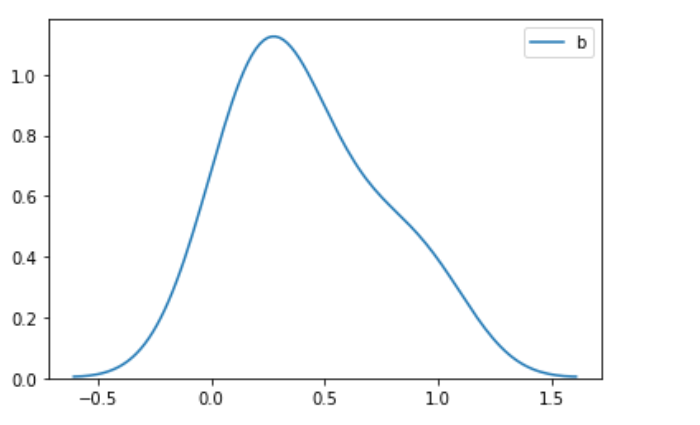
二、标准化
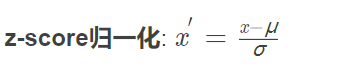
标准化后均值为0,方差为1.
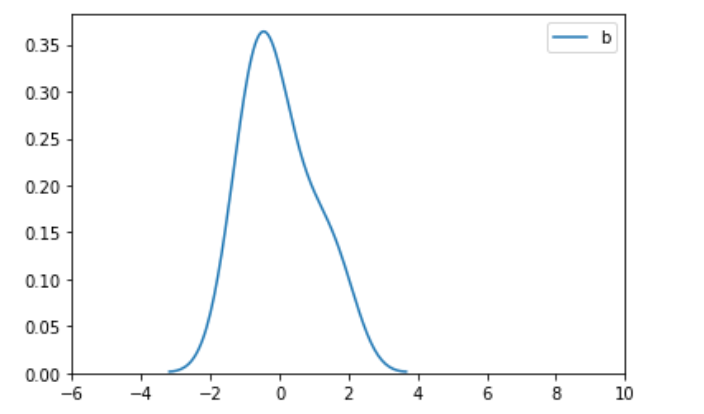
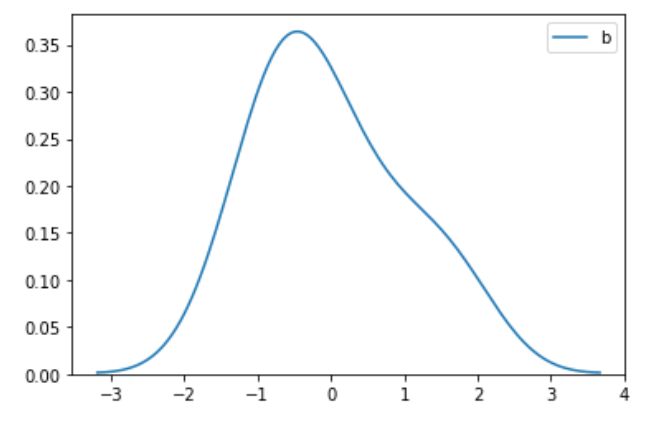
1)限制xlim(-6,10) 2)去掉xlim限制
三、结论
从上述归一化和标准化可以看出来,转换后数据的均值和方差都发生了改变:
1)均值发生改变可以理解为数据的坐标都进行了平移转换,均值其实也是随之一样转换。
2)方差的改变是因为数据都压缩在了更小的范围内了,所以方差都变小了。
3)通过画图去掉xlim的限制,我们可以看出转换后的图的形状跟原图的形状是一样的,也就是图的形状本质上没变,只是压缩在更小的空间范围内,从同一xlim范围看是变瘦了。
四、什么时候使用标准化,什么时候使用归一化?
使用标准化
如果对数据无从下手可以直接使用标准化; 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响 需要使用距离来度量相似性的时候:比如k近邻、kmeans聚类、感知机和SVM,或者使用PCA降维的时候,标准化表现更好 使用归一化
数据较为稳定,不存在极值 在不涉及距离度量、协方差计算的时候,可以使用归一化方法 两者都不需要:
决策树、基于决策树的Boosting和Bagging等集成学习模型对于特征取值大小并不敏感 有较多类别变量的数据也是不需要做标准化处理的。 五、在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的
标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。 标准化更符合统计学假设。对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。 举例看带有异常的归一化和标准化有什么区别:
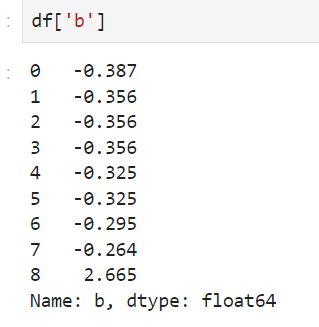
从中可以看出,带有异常值的时候,min-max归一化后,把前面的数据都压缩到了很小的空间,相差100倍了,但是标准化后却差别没那么大,这就是标准化对异常值没那么敏感。
再看另外一组图片:
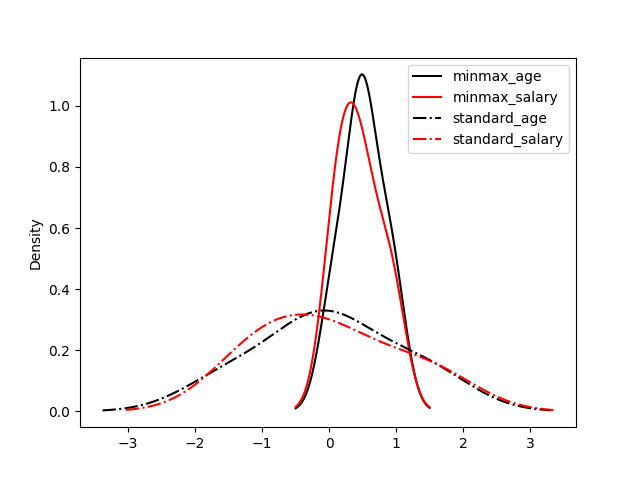
可以看出归一化比标准化方法产生的标准差小,使用归一化来缩放数据,则数据将更集中在均值附近。这是由于归一化的缩放是“拍扁”统一到区间(仅由极值决定),而标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系。所以归一化不能很好地处理离群值,而标准化对异常值的鲁棒性强,在许多情况下,它优于归一化。
参考:https://zhuanlan.zhihu.com/p/450496701
上一篇:《绿皮书》:一部真实的故事
下一篇:瑜伽培训学院排名(国内最大瑜伽培训学院)
最近更新影视资讯
- 韵府群玉
- 老年临终关怀护理集锦9篇
- 如何评价剧场版动画《和谐(harmony/ハーモニー)》原作:伊藤计划 ?
- 智人战胜尼人的决定性因素 是神灵崇拜与艺术品 在3万7千年前智人击败了远比自己强
- 沈阳参考消息(2017年1月11日)
- 密集架区密集架书库图书馆负一楼期刊阅览区中外文期刊图书馆一楼图书借阅区(A-H
- 费维光:脾胃病17方
- 土耳其身为伊斯兰国家,为什么允许“风俗产业”合法化?
- 高中教师教学反思
- 三观尽毁!90后公务员出轨50岁女上司,聊天言语暧昧,妻子怒举报
- 22应用心理学考研347 首师360有调剂院校吗?
- 铃木凉美女士,你仍期待同时收获怜爱与尊敬吗?
- 团建别墅 | 确认过眼神,是能疯一起的人!Boss,今年年会我们泡私家温
- 《归来》观后感
- 翻译伦理的重要性和译者荣辱观建设研究
- 高二语文期末考试测试题及答案
- 国医大师名单!在北京看中医该找谁,这下全知道!
- 这些年爱过的同人文(BG)
- 荷兰深陷风俗业?日本都要甘拜下风,为何能稳坐世界顶尖位置!
- 戴安娜25年前私密录像首次解密:自述性生活,全英国都被炸懵逼了
- 原创上官婉儿为什么必须死,她做的这件事太无耻,李隆基忍无可忍
- 「医药速读社」Paxlovid临床失败 礼来斥巨资引进Kv1.3抑制剂
- 她是韩国性感女神,靠出演“三级片”走红,今41岁韵味不减当年!
- 电影市场有望点燃 好莱坞大片排队上映
- 评荐《传染病(Contagion)》